

It’s been a while since my last proper post, but I’ve given a presentation last week that, I believe, deserves to be expanded into a post.
The presentation was about my current employer, the Very Group, transformation away from its legacy systems and processes, and the technology behind that modernisation.
My contribution to the presentation was specifically about how the Digital Customer Experience (DCX) tribe will re-architect our flagship e-commerce websites away from our ageing monolithic platforms towards a modern, composable, MACH architecture .
You can watch the whole presentation here:

In this post, I reproduce the slides (badly, as powerpoint export to GIF function is poo), together with additional thoughts I didn’t have time to cover during my slot.
The problem of the monolith

A monolithic platform such as Oracle e‑commerce ATG will always, sooner or later, lead to spaghetti logic.
A single codebase will cause well intentioned engineers to apply DRY principles, and shared components which will eventually cause logically independent business concerns to become coupled through shared code artefacts.
Eventually, on a large codebase such as the Very Group websites and underlying business systems, this coupling makes it near impossible to experiment or accelerate the deployment of new features, as every single code change risks impacting other unrelated features.
Releases have to be batched, with sufficient time in between to allow for regression testing. Automating these tests is itself difficult as each combination of features causes an explosion in the number of regression tests required.
All of this is incompatible with moderns ways of developing and deploying software, which privilege small and frequent feature releases with quick customer feedback loops to adjust the direction of travel before prioritising the next feature.
Breaking down the monolith - bit by bit

We do not have the luxury of recreating our platform from scratch. We must break the monolith down into its constituent parts before we can start replacing these, one by one, like the planks of Theseus’ ship, without impacting our customers’ experience.
Ship of Theseus
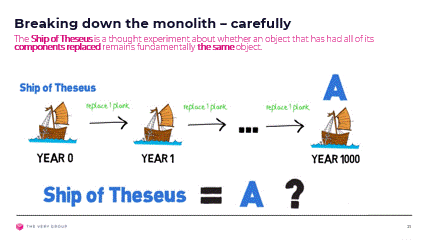
This thought experiment from the philosophers of ancient Greece asks whether an object that has had all of its components replaced remains fundamentally the same object.
Putting aside the philosophical question, we will inspire ourselves from that approach and replace our monolith not through one big bang all or nothing approach, but very gradually, plank by plank, so that our customers will at all time remain unaware of the transformation.
Unfortunately, by definition, a monolith is not made of individual components, so, how will we identify the bits we can replace?
We will slice and dice the monolith along logical boundaries that might not exist in the codebase but are meaningful to our team.
Logically distinct customer journeys

Our engineering squads are already organised along the journeys our customers take through our website. The presentation and business logic associated with let’s say product discovery (browsing for and eventually selecting a specific product) is logically distinct from customer onboarding (creating an account) or account management.
These journeys are therefore an easy way to slice through the responsibilities of our monolith.
Logically distinct architecture layers
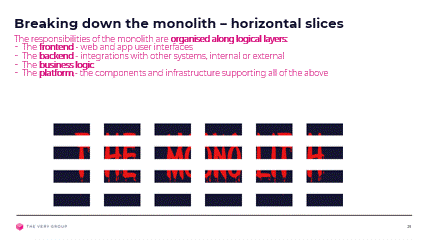
Although monolithic, our platform is layered, with distinct areas of the codebase dealing with front end, business logic and integration with other systems. Again, the codebase itself will have undesirable dependencies, but these architectural layers are logically independent and another easy way to slice through the monolith.
Logically distinct bounded contexts
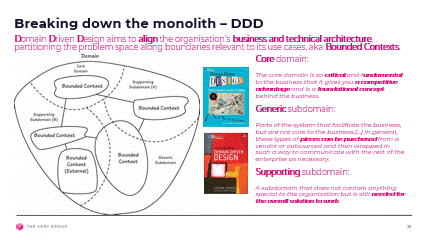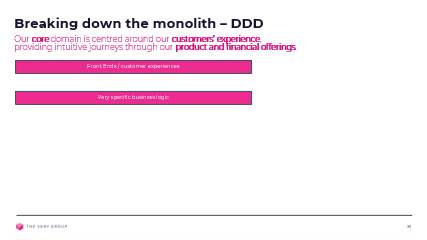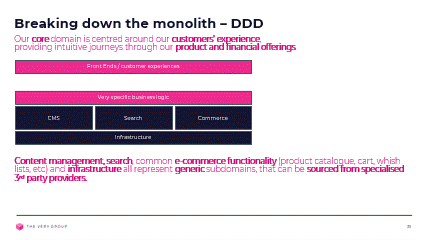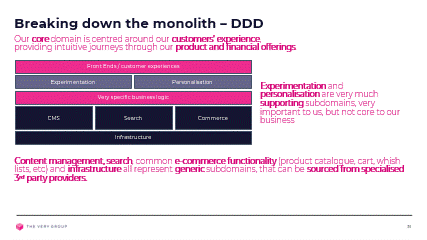
We now look at our entire solution, or rather the problems we are solving with that solution. According to Domain Driven Design (DDD) This ‘problem domain’ can be broken down into subdomains that are either core, generic or supporting:
-
The core domain is what truly differentiates us from our competitors, our bread and butter, our Unique Selling Point (USP). This is what matters to us as an organisation and where we want to put in all our efforts.
Our core problem here at the Very Group is how to provide the best digital customer experience, across multi channels, and make it as easy as possible to find and buy the right product, at the right price, with, if required, financial options, while meeting all our compliance requirements.
-
On the other hand, many problems in our domain are quite generic across our industry and actually quite difficult to solve in any way that would differentiate us from our competitors.
Instead, we are better off partnering with 3rd parties who are happy to treat these problems as their core domain and for us to simply consume those 3rd parties’ solution to these problems.
-
finally, supporting sub domains are problems that we must solve in order to address our core problems, but will not in themselves differentiate us from our competitors.
Within these domains, we can now identify problem area that are specific enough from other problem areas. Given problem X, let’s say “data associated with a customer”, we can clearly state that it belongs in the “customer” problem area, and not the “shopping cart” one.
We can draw a clear boundary around each of these problem areas, and deal with each independently from others.
This is of course a gross over-simplification of what Domain Driven Design calls “Bounded Contexts”, see Eric Evans’ original book or the much more actionable follow-up by his colleague Vaugh Vernon for a much better explanation.
Strangler fig pattern
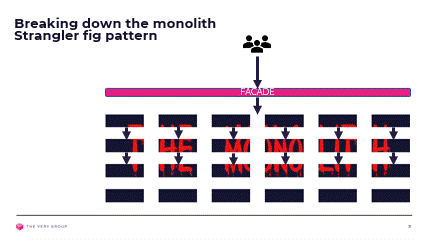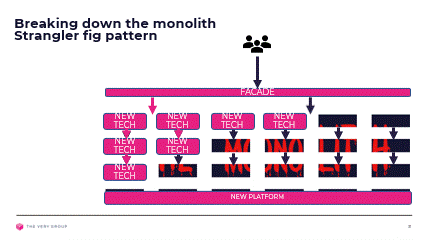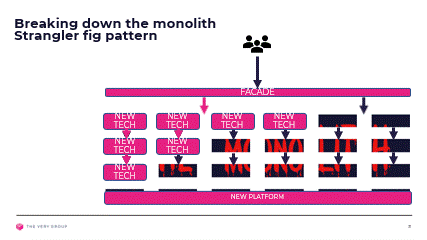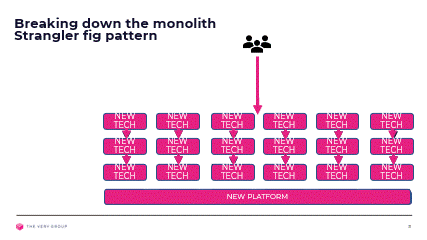
We have now sliced and diced our monolith into bounded contexts, mapped these to our customer journeys and architecture layers and decided whether they address a core, generic or supporting problem. We now need to start reimplementing them away from the monolith, and introduce them into the overall solution without the customer being aware.
We will achieve this by leveraging the Strangler Fig pattern, and introducing façade components in front of our monolith, tasked with shunting traffic away from the monolith toward our new components as and when these become available.
As we reimplement more and more of our solution on our new architecture, the façade will shunt more and more requests away from the monolith, until eventually we will be able to remove it and the façade altogether.
Again this is a gross over simplification of the full decomposition process. There will be multiple façades, between architecture layers, and where our customer journeys are not truly independent, each trying to expose a nice clean interface over the spaghetti logic underneath it.
MACH target architecture
Once we have a strategy to break up the monolith, we can target a modern, non-monolithic, composable architecture.
MACH is a cute acronym coined in the retail industry to market SaaS platforms that can be composed into best-of-breed e-commerce solutions.
It stands for Microservices, API-first, Cloud native SaaS and Headless components and is very much the pattern you’d use, regardless of industry, to build a modern business application
Microservices
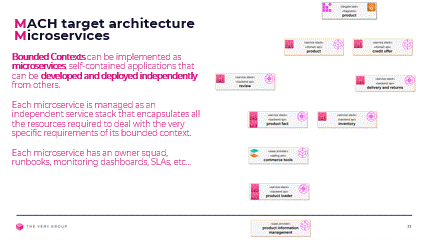
Microservices are the technical implementation of the bounded contexts we mentioned earlier:
Having identified tightly defined problems areas with a clear boundary between what does and doesn’t pertain to a specific problem, we can design and implement specific solutions to these specific problems. These solutions should each be applications in their own right, managed entirely separately from each other, truly independently.
Instead of one big monolithic solution to all our problems, we will have much smaller (hence the micro- prefix) individual solutions to individual problems.
NB: Yet another over-simplification of what is an architecture style in its own right.
APIs and Events
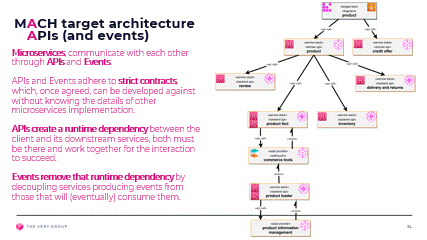
To be truly independent from each other, microservices should only communicate (exchange data) via APIs or events. APIs, Application Programming Interfaces, are basically an agreed contract between a service and its clients, that defines every single detail of the communication, from the protocol, to the data exchanged, the format that data will take, how errors will be returned, etc…
Having agreed on that contract, both sides, service and clients, can implement it whichever way they see fit, independently from each other, using whatever technology or framework they prefer.
APIs do however imply a client-service relationship whereas the client calls the service’s API and expects a response. Even an asynchronous API will follow that pattern, but broken over 2 separate exchange, one for the request from the client, which is immediately acknowledged by the service, and a later one for the response, from the service to the client, which is also acknowledged by the client.
If either side is not present, or fails during the interaction, the communication will fail.
Events, on the other hand, remove that runtime dependency, by totally decoupling the event publisher from its eventual consumers. Events are fired into the ether (actually a bus or hub built into the overall platform to be shared across components) without knowing, or caring as to who will consume them, or when. The 2 sides of the communication do not even need to be running at the same time : the publisher might run just long enough to fire an event and then stop, naturally or catastrophically, without it affecting the consumers.
This is a very bad explanation - I need to rewrite this bit.
From a MACH architecture point of view however, what matters is that APIs and Events allow microservices to be developed, deployed and managed independently of each other.
Cloud native components and technologies
Cloud native can mean different things to different people, or in different contexts. On the one hand, you have the definition from the Cloud Native Computing Foundation:
“Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.”, and its infamous ‘cloud native landscape’.
On the other, we have MACH’s definition:
“Software as a Service developed, designed and deployed as cloud-native applications are composed of several independent services. The independence of each service introduces the ability to maintain and scale, in isolation, horizontally rather than vertically.”.
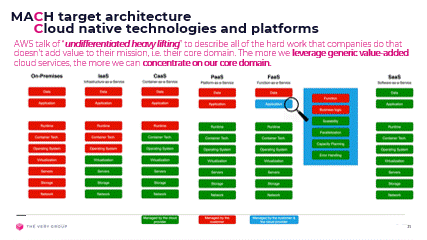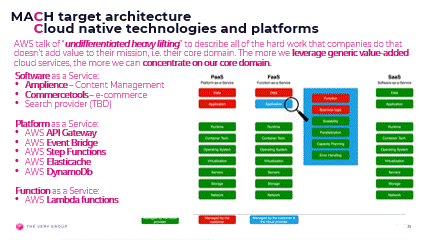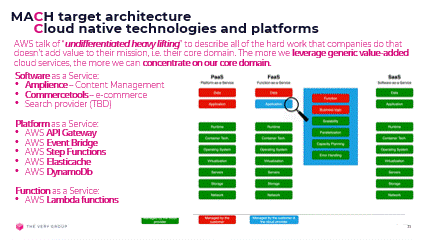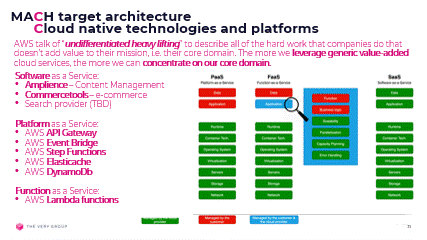
Personally, I like to think of cloud native as leveraging value-added services from the cloud, i.e. work on the right hand-side of this diagram, from SaaS to PaaS:

SaaS: 3rd party software incorporated into our architecture to provide generic domain functionality, should be consumed ‘as a Service’, meaning via APIs or events, and have near zero infrastructure footprint.
FaaS: the code we implement to provide core domain functionality, should be, as much as possible, be implemented as Functions, allowing us to concentrate on our core problem and leave all the “undifferentiated heavy lifting of triggering, running and scaling (up or down) that code to our cloud provider.
PaaS: the platform we deploy and run our software on should itself be accessed ‘as a Service’. Storage, queues, event infrastructure, load-balancing, monitoring, alerting, security, and all those other myriad concerns, should again be managed on our behalf by the cloud provider, with as much complexity as possible entirely hidden or abstracted away from us, to again, let us concentrate on our core domain.
During the Hackajob presentation, an attendee asked about multi-cloud, meaning the ability to deploy our software on any or all the available cloud vendors. It is important to note that “multi-cloud” is only possible if building on the left hand-side of the diagram above, limiting yourself to Infrastructure as a Service (IaaS) or Containers as a Service (CaaS) and is actually the polar opposite of leveraging value-added services.
To be truly Cloud Native means working together, and trusting your cloud and SaaS provider, and believing they are much much better than you at running infrastructure at scale.
Headless components and services

In order to keep control of all aspect of our Customers experience, it is essential that all the components we incorporate into our solution remain completely Headless, meaning have no user interface, and do not impose any specific user workflows.
As stated above, all interactions must be ‘as a Service’, i.e. via APIs or events, and these must not convey any element of user interaction, be it user messages or any sort of content formatting, and make no assumption as to the user journey that led to these interactions, or whether there is indeed an actual user involved.
Technologies behind our transformation
I am not actually going to expand on these much more here, give myself some material for future blogs.

SaaS partners
AWS PaaS value-added services
- Lambda functions – business logic
- API Gateway – REST APIs
- EventBridge – events driven services
- Step Functions – orchestration & integration
- ElastiCache – Redis & Memcached
- DynamoDb – NoSQL data storage
DCX technology stack
- Javascript + typescript – development language
- React + fastify - web UI
- Kotlin & swift - native apps
- Storybook – UI Development
- Node.js – microservices
- Open API, Supertest & PACT – API design & testing
- Lighthouse & cypress – end-to-end testing
- Elastic - monitoring (logs & APM & RUM)
- Terraform - Infrastructure as Code
- Fastlane – app release management
- Gitlab & Jenkins – CI/CD pipelines